‘May the force be with you’ and other fan fiction favorites
Starting with Star Wars, Penn researchers create a unique digital humanities tool to analyze the most popular phrases and character connections in fan fiction.
Penn researchers (from left) James Fiumara, Peter Decherney, and Scott Enderle created a unique digital humanities tool to analyze the most popular phrases and character connections in fan fiction based on blockbuster film series.
As a new Star Wars movie hits the multiplex, Penn researchers are launching a new computer-based tool to better understand fiction written by fans based on that blockbuster series and several other famous film franchises.
The Penn team started with the script of “Star Wars: The Force Awakens” and created algorithms to analyze the words in the script against those in millions of fan fiction stories. The unique program identifies the most popular phrases, characters, scenes, and connections that are repurposed by these writers and then displays them in a simple graph format.
“We had a lot of theories about how fandom might be changing now, and we were interested in studying that,” says Peter Decherney, English professor and director of the Cinema and Media Studies Program. “We also thought that we could use the computational methods and algorithms of digital humanities to analyze the millions of fan works out there.”
Decherney initiated the project, combining his knowledge of film, copyright law, and literature. “I thought it would be a simple project,” he says. “Where in their stories do the fans reuse and rework movie dialogue?”
In the spring of 2017 he recruited two of his former Ph.D. students who are now in the School of Arts and Sciences. One was Scott Enderle, a digital humanities specialist also with the Penn Libraries, who has the rare combination of a Ph.D. in English and extensive mathematical and computer science skills. He is perfect to “figure out what’s possible and how to get there,” says Decherney. He also selected James Fiumara of Penn’s Linguistic Data Consortium, an expert in language study and a former film studies professor.
It took nearly three years, banks of laptops running around the clock for weeks, coding by a half-dozen students, and countless hours making innumerable decisions, but they did it: all 10 “Star Wars” movies, the three “Lord of the Rings” films, the three “The Hobbit,” films, and the 10 “Harry Potter” movies. In all, they analyzed 26 film scripts and 5 million-plus fan fiction works, ending up with a total of more than 2 billion words scanned. “Star Wars” scripts alone were together more than 460 million words.
“We kept paring down the project,” Decherney says, “making it as simple as we could. It still took one computer days or even weeks to analyze a single script.”
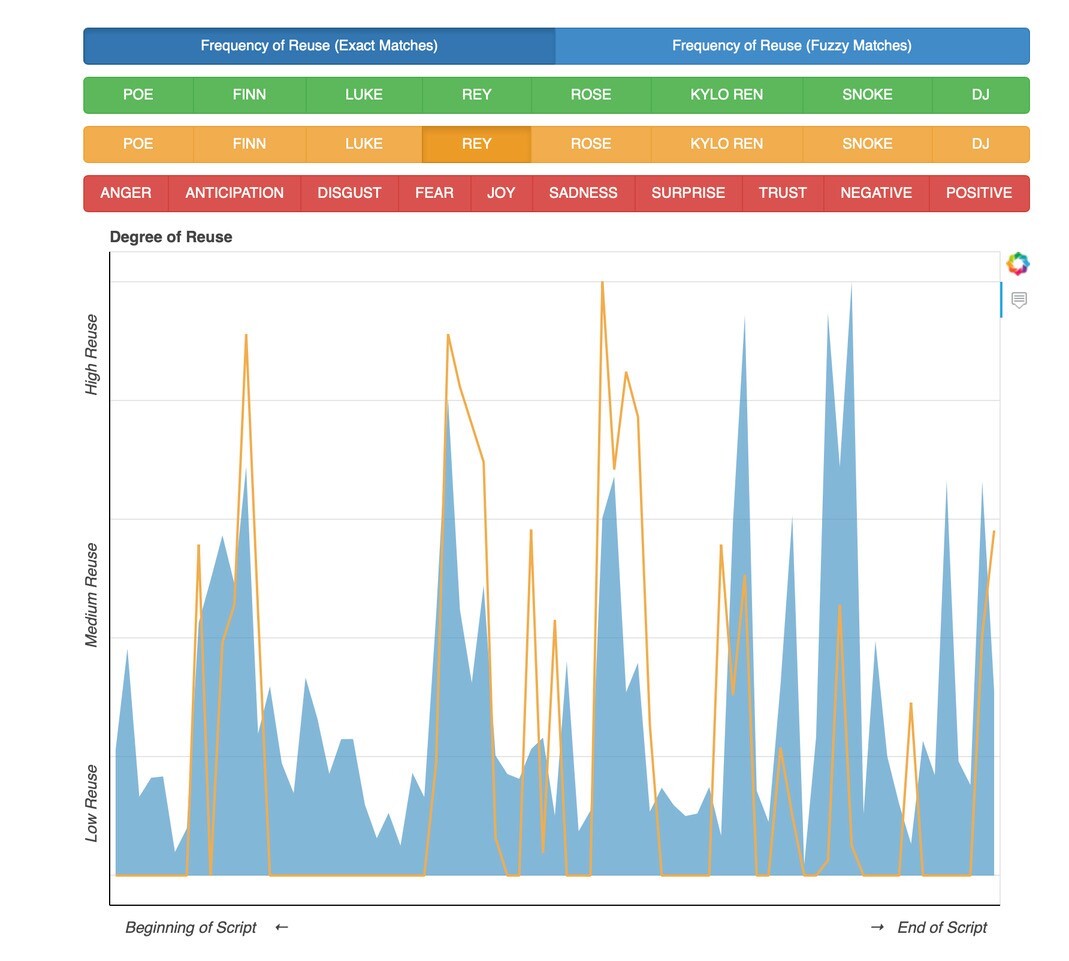
Using the new fan engagement meter developed by the School of Arts and Sciences, media scholars and movie fans can measure fan's reuse of dialogue in "Star Wars: The Last Jedi" (blue), for example, and compare it with dialogue spoken by the main character Rey (orange). Which characters do fans engage with the most in fan fiction and why?
It is possible to view the script of each movie and the phrases that are most used by fan fiction writers, tracking characters and combination of characters through each line. Another feature makes it possible to compare fan reuse of language with the emotional arc of the movie scripts. Do angry moments or action scenes, for example, generate more fan engagement?
“The fan engagement meter doesn’t come to interesting conclusions on its own, but it prods its users to ask novel questions and looks for answers in places they may have ignored before,” says Stewart Varner, managing director of Penn’s Price Lab for Digital Humanities, a partner in the project.
“Is there a pattern to when quotable lines appear that is detectable across films? What can we learn about films based on what relationships between characters resonate with fans? Not only will this tool suggest the question, it can also give you some promising clues about where to start looking for answers,” Varner says.
Fiction by fans
The repository of stories the team used is Archive of Our Own, a “fan-created, fan-run, nonprofit, noncommercial archive for transformative fan works” which has 5.4 million works and 2.2 million users.
An Archive co-founder, Francesca Coppa, professor of English and director of the Women’s and Gender Studies Program at Muhlenberg College, taught Cinema and Media Studies classes at Penn in 2013, including several on fan culture. “I do think the project is interesting if it tells us about the pivotal lines or moments that fans reread and hang their own inventions on,” she says. “I am curious to see if it reveals commonalities of stories likely to spawn both fan works and transmedia universes.”
The Marvel movies have the most fan fiction, but the team decided they were too fragmented for this project, Decherney says. So, they chose the next-largest communities of fan fiction works, numbering in the hundreds of thousands for each film.
“A common practice among fans is to take minor characters and explore their stories,” says Decherney. Often the characters fans are most drawn to are women and minorities who historically have not been major heroes in big movie franchises. The works range from a couple of pages to novel-length stories of more than 100,000 words.
Fan fiction also creates community. The writers connect with each other online and role play. “A lot of fan fiction looks like a conversation,” Decherney says. He thinks other academics, fans, and even movie studios might be interested in using the new tool to discover more about these writer communities.
Many writers in film and television have landed those jobs through their success in fan fiction communities, Decherney says. Studios that once fought against these works are now keenly interested in what the fans think, how they react, what they are looking for in the next sequel.
“If you go to the writers room of a popular TV series, you will find that many writers started out writing fan fiction," Decherney says. “Hollywood is paying attention, too.”
The three Penn researchers (from left) James Fiumara, Scott Enderle, and Peter Decherney worked nearly three years to create the fan engagement meter, starting with the film series Star Wars, Lord of the Rings, and Harry Potter.
Creating the computer tool
Decherney places the project in the field of “distant reading,” the analysis by computers of massive amounts of text. It’s the opposite of the “close reading” often done in literature classes, when students might analyze one paragraph of text. “We can now use computers to analyze more texts than anyone could ever read in a lifetime,” he says.
Critical to the team’s quest was deciding the length of the phrase they would ask the algorithm to search for in the texts. After many attempts, from three words to 15, they decided on six. The algorithm looks for six-word matches and clumps of activity across those matches.
One of the strongest and most popular six words used by fans are, not surprisingly, “May the force be with you” from Star Wars. Another popular phrase is “A long, long time ago in a galaxy far, far away.”
For Harry Potter fans, a very favorite scene to rework is in the first movie, “The Sorcerer’s Stone,” when Harry and his friends are chosen for their Hogwarts Houses by the magical Sorting Hat.
The Penn team had to decide how to represent the data, toying with different approaches, ultimately deciding on a simple line graph, using colors to distinguish between the reused phrases, the characters speaking in the scene, and the emotional qualities of the text.
In "Harry Potter and the Sorcerer's Stone," the Sorting Hat sequence is by far the fans' favorite passage to rework and imagine alternatives to in their fiction.
Enderle made it all happen. “My role was figuring out how to translate the high-level goals that we have from the project from a humanistic perspective into the super-concrete instructions that we have to give the computer,” he says.
The tool had to be tailored for the humanities, using computational methods to ask questions that are different than those social scientists would ask, Decherney says, such as the construction of narrative, engagement with character, and emotion and plot.
That’s just what the Price Lab, which funded the student internships, is all about. Sophia Ye, a senior from Newtown, Pennsylvania, was a summer Price Lab intern on the project.
The experience “had a really big impact” on her decision to major in business analytics in the Wharton School and minor in computer science, she says. “When I first started the internship, I didn’t know anything about web development. I had to learn a lot of different development languages,” she says. “I got a lot of technical skills.”
Much of what she did on the early version of the program was to work on how the data would be represented, searching for the most optimal viewing to make the data meaningful for people. “I think it’s super cool that I was a part of this project, and I’m really excited to see where it goes,” she says.
Several other students worked on the project during the three years. “The students have been such great contributors doing the programming and also helping to solve issues about how to represent the data,” says Enderle. “It’s not just the algorithms and the math and the programs to do the calculations. It’s how do you represent it on a screen.”
Fiumara contributed by conceptualizing what features should be incorporated into the model. “I brought in the perspective from what’s going on in the world of natural language processing and machine learning and computational linguistics,” he says.
For example, discerning the difference between commonly used phrases and those that have meaning in the context of the plot. “I love you,” is a common phrase. But it has great meaning when Princess Leia says it to Hans Solo in “Star Wars: The Empire Strikes Back,” and he replies, “I know,” an exchange that became one of the most famous from the iconic series.
“We have a great team, and I always look forward to brainstorming and problem solving with Scott, James, and the many students who working on the project,” Fiumara says.
Creating the fan fiction meter required countless decisions and the three researchers worked well together coming up with solutions.
Fan fiction discoveries
So, what does the fan engagement meter show? “Often what the writers do in fan fiction is take characters who aren’t well developed in a film and they explore them more,” Decherney says.
There were some surprises. The prevailing view was that in “Star Wars, The Force Awakens” the pairing of General Hux and Kylo Ren was the most popular for fan fiction. The engagement meter shows there are three other pairings that are used just as frequently in that film.
The team also wanted to explore why the pairings were interesting to the fans and what got them excited about writing those stories.
“They were the ones that had the least backstory. Fans really wanted to explore that,” says Decherney. “What about their emotional lives? What about their sex lives? Those are all the kinds of things that fans want to know about, the things that are not represented for the most part in mainstream media.”
Fan fiction future
“When we started to talk about our findings at conferences,” Decherney says, “other scholars asked when they could use the tool.” So, the team set out to make the Fan Engagement Meter available to researchers and fans as soon as they could. “We hope people will contribute to it by suggesting things we can add,” Decherney says.
They plan to add more franchises and films, starting with the new movie “Star Wars: The Rise of Skywalker,” to be released Dec. 20. There is a place on the website for scholars and fans to submit properly formatted scripts for analysis by the Fan Engagement Meter.
Predictive models are one possible next iteration for the tool. “Trying to find ways to see if there are global patterns in what fans do or don't reuse. And if so, what are they?” Fiumara says. “And then the second part would be: Can we develop a predictive model from this data that might predict how the fans might engage with it?”
The tool could be used for myriad research projects, such as comparing fan fiction with novels or any body of written work against another.
“It’s important to recognize that all authors—not just fans—are always drawing inspiration from other works and borrowing, transforming older works. And this tool will give us a way to talk about the creative process more concretely,” Decherney says.
“This is just version 1.0. We know that it has a long way to go. But we’re really looking forward to having people use it and finding ways that we didn’t even expect it could be used.”
Nanoparticle blueprints reveal path to smarter medicines
New research involving Penn Engineering shows detailed variation in lipid nanoparticle size, shape, and internal structure, and finds that such factors correlate with how well they deliver therapeutic cargo to a particular destination.
A generous gift from alumni Glenn and Amanda Fuhrman brings the work of internationally acclaimed artist Jaume Plensa to the University of Pennsylvania. The latest addition to the Penn Art Collection expands Philadelphia's public art.
A massive chunk of ice, a new laser, and new information on sea-level rise
For nearly a decade, Leigh Stearns and collaborators aimed a laser scanner system at Greenland’s Helheim Glacier. Their long-running survey reveals that Helheim’s massive calving events don’t behave the way scientists once thought, reframing how ice loss contributes to sea-level rise.








{kind=link}
{kind=link}
{kind=link}
{kind=link}