Who to vaccinate first? Answering a life-or-death question with network theory
Researchers from Penn Engineering and Penn Medicine have collaborated to determine the best theoretical strategy for a vaccine rollout.
Engineering and medical researchers at Penn have developed a groundbreaking framework that can determine the best and most computationally optimized distribution strategy for COVID-19 vaccinations in any given community. Published in PLOS One, the study addresses one of the most critical challenges in pandemic response—how to prioritize vaccination efforts in communities with individuals of different risk levels when supplies are scarce and the stakes are high.
The research team, comprised of Saswati Sarkar, professor in electrical and systems engineering (ESE), Shirin Saeedi Bidokhti, assistant professor in ESE, Harvey Rubin, a practicing physician at the Perelman School of Medicine and professor of infectious diseases, and ESE doctoral student Raghu Arghal, designed their framework to be able to account for enough population complexity to determine the best and most applicable vaccination strategies, but not so complex that it becomes inaccessible to public health offices without high-powered supercomputers. What the researchers have created a highly adaptable framework that provides effective and unique strategies in a matter of seconds and only requires the computational power of a personal laptop.
Determining the best theoretical strategy for a vaccine rollout that includes all influencing parameters such as individual health metrics, location limitations and doses required, would typically take months or more, even with the massive computational power available today. This is because the size of communities over which such rollouts would need to be optimized can easily reach one million. For example, communities in the boroughs of New York City range anywhere from 0.5 to 2.7 million people.
“We needed an approach that would provide strategies on a more relevant timeline and require less computing power,” says Sarkar. “This was especially important to us as we wanted the framework itself to be accessible to low-resourced and remote communities, which are typically the most affected by disease outbreaks. We had to approach this real-world problem more practically while still using network theory tools that captured enough population heterogeneity to arrive at a meaningful and useful strategy.”
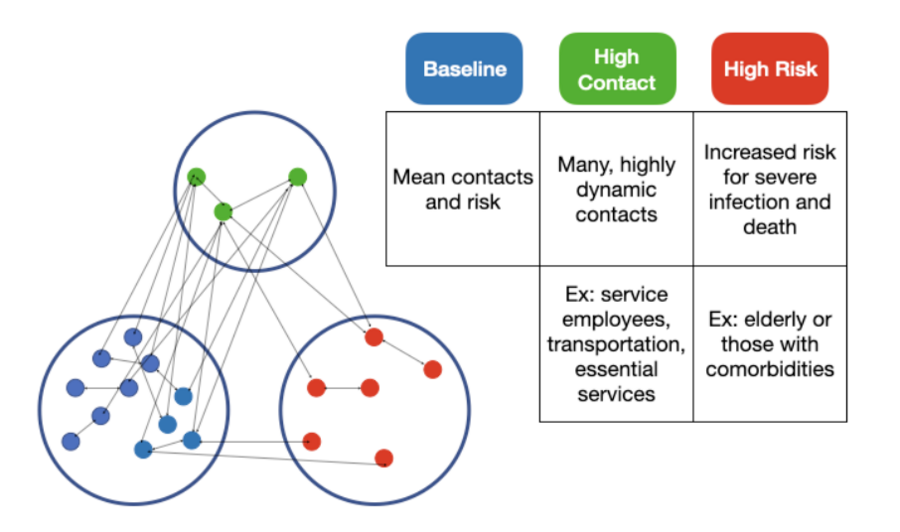
To achieve this level of complexity, the researchers defined three groups; a high-risk group, a high-contact group, and a baseline group.
With this grouping, the team was able to use a numerical methodology with just the right amount of complexity that can offer unique and effective strategies for any given community.
Novel plant-based approach to a better, cheaper GLP-1 delivery system
Research led by Penn Dental’s Henry Daniell investigates the use of a lettuce-based, plant-encapsulated delivery platform as a new oral delivery of two GLP-1 drugs previously approved by the FDA in injectable form.
No brain, no gain: Neuronal activity enhances benefits of exercise
Research led by Penn neuroscientist J. Nicholas Betley and collaborators finds that hypothalamic neurons are essential for translating physical exertion into endurance, potentially opening the door to exercise-mimicking therapies.
In honor of Valentine's Day, and as a way of fostering community in her Shakespeare in Love course, Becky Friedman took her students to the University Club for lunch one class period. They talked about the movie "Shakespeare in Love," as part of a broader conversation on how Shakespeare's works are adapted.
In Becky Friedman’s English course Shakespeare in Love, undergraduate students analyze language, genre, and adaptation in the Bard’s plays through the lens of love.
Beating the heat: Designing cooling for bodies in motion
Dorit Aviv, director of Weitzman’s Thermal Architecture Lab, studies how humans, technology, and design intersect, paving the way for the development of novel approaches to cooling people efficiently.




{kind=link}