This summer, rising second-years Audrey Keener and Nicholas Eiffert worked in the lab of Penn linguist Jianjing Kuang studying vowel articulation in song. For 10 weeks, they ran an in-person experiment and built a corpus of classical recordings by famous singers.
Rising second-years Audrey Keener (left) and Nicholas Eiffert spent the summer interning in the lab of Penn linguist Jianjing Kuang, and working with third-year Ph.D. student May Chan. The work, looking at vowel articulation in singing, sits at the intersection of interest for the students, who are both musicians who study computer science.
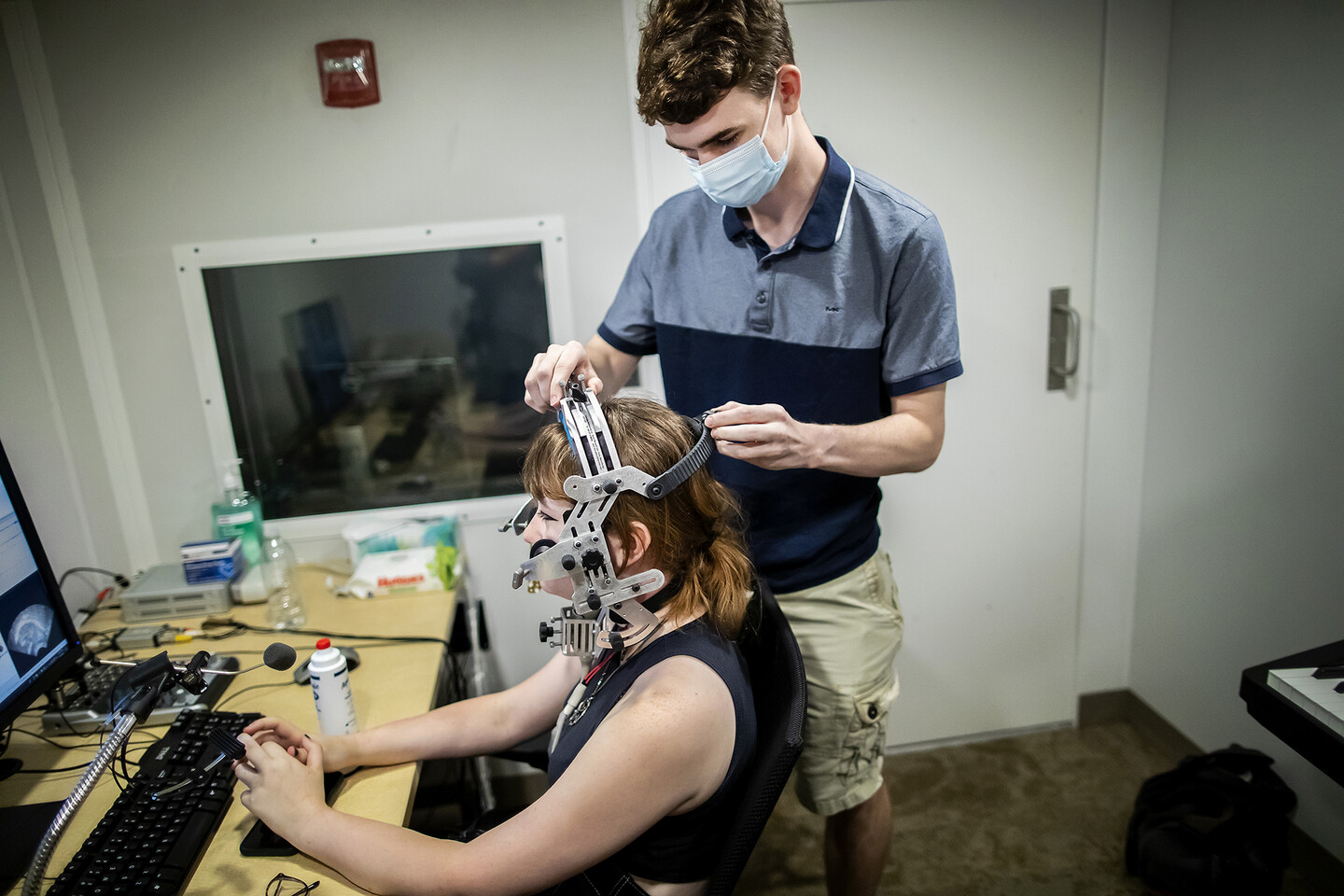
In the Penn Phonetics Lab in early August, rising second-year Nicholas Eiffert places a metal contraption over the head of Maggie Compton, a high school friend of his who has agreed to participate in the study he’s helping facilitate.
“We’ve affectionately named this the cage,” he says as he checks the alignment of the ultrasound probe on Compton’s chin. “That’s your tongue,” he says, pointing to a moving image on the facing computer screen. “This all looks pretty good,” confirms Audrey Keener, another Penn rising second-year working in the lab.
During the next 20 or so minutes, Compton reads then sings a series of words, each one recorded by the computer. The ultrasound captures images of her tongue placement in the mouth, and an electroglottograph (EGG) strapped around her neck measures vocal fold vibrations.
The experiment is part of work led by Penn linguist Jianjing Kuang aimed at understanding how people create vowel sounds when they sing. This summer, through the Penn Undergraduate Research Mentoring (PURM) program offered by the Center for Undergraduate Research and Fellowships, Keener and Eiffert recruited participants for the study, ran sessions, and compiled recordings of famous singers to analyze the same auditory components they were measuring in person.
“Music has a privilege in auditory processing, and singing is a special case of speech production and perception,” Kuang says. “Speaking uses minimal effort, in terms of articulation and processing. But people have to train to be good singers. In this project, we want to push the limit, to look at what happens when human beings maximize their effort and try to achieve the best acoustic effects.”
Building on a small sample
This summer’s project expands on a small sample of local singers that third-year linguistics doctoral student May Chan had previously recruited to study vowel articulation in singing.
She and Kuang are still working through that analysis, but they did notice some patterns early on. “For sopranos it’s obvious. When they sing very high notes, the only vowel they can produce is ‘aaaaahhh,’” Kuang explains. “For the lower vocal range, there has to be greater modification.” Because vowels vary in what the mouth does to produce them, singers of different vocal ranges must employ different strategies to sing them.
Eiffert situates a headset on participant Maggie Compton. The metal contraption holds an ultrasound probe in place under Compton’s chin, to capture images of her tongue placement in the mouth.
Getting a clearer picture of such tactics would require analyzing the interaction between tongue placement and pitch in more people. Inspired by the enthusiasm of students in a class she taught this past spring called The Phonetics of Singing, Kuang decided to broaden the study and offer two PURM internship spots this summer.
For Keener and Eiffert, the opportunity sat at the intersection of their interests. Keener, a computer science major from Bethel, Connecticut, plays piano and flute; Eiffert, a double major in math and computer science from Bordentown, New Jersey, used to play saxophone and took music theory classes in high school.
Kuang invited the two Penn undergrads to join her lab, then divided the project into two major components, one focused on lab work, another on compiling a corpus of famous singers. The students began their 10-week internship on June 7.
The study’s components
With oversight from Kuang and Chan, Keener and Eiffert spent much of their time running the experiments, which took place in a soundproof room on the third floor of a Walnut Street building. The pandemic had left the equipment mostly dormant for several years, so getting it up and running again required some trial and error.
“Setting up the lab to run articulatory experiments felt like a big task,” Chan says. Yet the trio was up for the challenge, taking turns as faux participants and testing the equipment with run-throughs of songs and sounds, like “Twinkle, Twinkle Little Star” and “aaahhhh” or “helllllooooo.”
With the set-up squared, they began bringing in participants—minimal singing skills necessary—who would get connected to the computer via a headset that held an ultrasound probe snugly under the chin. A Velcro strap held an EGG loosely around the neck.
Music has a privilege in auditory processing, and singing is a special case of speech production and perception.
Penn linguist Jianjing Kuang
Each person would start by speaking a set of words, then move into singing scales, not the do-re-mi kind, but word sets Chan had developed. Starting at the bottom of their vocal range, participants would go through one series—bot, boot, bat, beat, bet, bought, for example—move up a note, then repeat until they could go no higher. They completed the exercise five times, with different word sets each time. “We took turns having somebody outfit the participant and run recordings, while the other person was at the piano playing the pitches,” Keener says.
Eiffert also led a secondary aspect of the work, compiling classical recordings the team could use to study the same vowel articulation in singing. “I’ve been going through this huge database to find songs that are vocal-only or vocal and piano or guitar,” he says. “Those can be used to see how vowels change as someone’s voice pitch changes.”
This summer, the Penn Phonetics Lab team ran the in-person experiment with 17 people. To date, the corpus Eiffert is building has some 500 recordings from around 25 singers.
Understanding vowel articulation
The point of all this research is to get at what happens when someone makes vowel sounds, which are the most discernible part of speech, according to Kuang. “When we speak, we have consonants and vowels,” she says. “Consonants are mostly just noise. The most mechanical or vocalic part of speech is the vowel. We focus on vowels to get a rich acoustic analysis.”
Chan sees implications for both linguistics and music research. “On the linguistic end, work on singing helps us understand the full potential of the human voice and its relationship with linguistic structure,” she says. “On the music side, experimental techniques for studying singing will allow for a more systematic way of describing musical genres and techniques across cultures, capturing the unique ways our vocal tracts are used.”
Beyond that, more insight into this type of speech production could reveal information about how the human brain functions. “It’s connected to the theoretical understanding of how the human vocal tract works,” Kuang says. “The brain and auditory system work together to perceive sound. Better understanding this will allow us to potentially help people with hearing loss, too.”
Though the research continues, Keener and Eiffert have now finished their summer work in the lab. It remains to be seen whether they’ll rejoin the lab this fall—Kuang has extended an invitation—but they both express gratitude for the experience. “It was great going through the process of figuring out a project, getting it to work smoothly,” Eiffert says.
That ease is on display back in the lab in early August. Eiffert reassures Compton, his friend and that day’s participant, that many people need multiple tries for the scales. He checks that she’s comfortable. Keener looks on from the piano, offering input and gently pinging each key. At session’s end, they’ve generated more data to add to the larger set, moving one step closer to unlocking the connection between singing, speech production, and the brain.
Penn physicists led by Bo Zhen have created hybrid light-matter particles that interact strongly enough to compute, pointing toward ultrafast, low-energy optical AI hardware.
Penn’s newest supercomputer is transforming research
Penn’s first campus-wide HPC and AI cluster, “Betty,” is expanding access to powerful computing, enabling groundbreaking projects, and fostering new collaborations across disciplines.
A bioengineered bean gum from the lab of Penn Dental’s Henry Daniell is found to reduce the levels of three microbes associated with head and neck squamous cell cancer to almost zero, without affecting the beneficial bacteria normally found in the mouth.
Fighting oral cancer with bioengineered chewing gum
Research led by Penn Dental’s Henry Daniell shows that antiviral and antibacterial chewing gums reduce the levels of three microbes linked to worse outcomes in oral cancers, paving the way for more effective and affordable therapies.
The performing arts at Penn: Process, practice, and purpose
In the vivid tapestry of performing arts groups at Penn, students prepare for their performances while simultaneously enriching their college experience.





{kind=link}